home
> blog
>> 746
| [previous] / [up] | [overview] | [down] / [next] |
Sun Apr 01 11:03:28 2012 GMT: Run, Christof, Run
Thu Mar 29 20:43:00 2012 GMT: boost asio 1.46.1 vs. boost asio 1.49.0
Tue Mar 27 18:19:40 2012 GMT: Opera 11.62
Well, this release fixes a security issue I reported about 3 months ago...
Sun Mar 25 00:31:10 2012 GMT: Overhead and Scalability of I/O Strategies
Having briefly looked at epoll vs. kqueue on Linux and FreeBSD/NetBSD, I'll now focus a bit more on Linux and this time I am adding some real concurrency into the mix in the hope of seeing some speedup with multiple threads.
The basic test set-up is similar to what we had previously: sending 4-byte datagram packets between a socketpair - but this time we also want to introduce some concurrency and use 16 socketpairs in a second test. And as a test machine we are using a quad-core Intel i7-2600K @ 3.4 Ghz (with hyperthreading enabled - so we get 8 hardware threads).
So in a first test we compare the performance of a blocking send/recv loop, a hand-written epoll loop, boost asio (1.46) and my own async abstraction when changing the number of worker threads (NB: for the blocking send/recv we always use a fixed number of threads equal to the number of socketpairs).
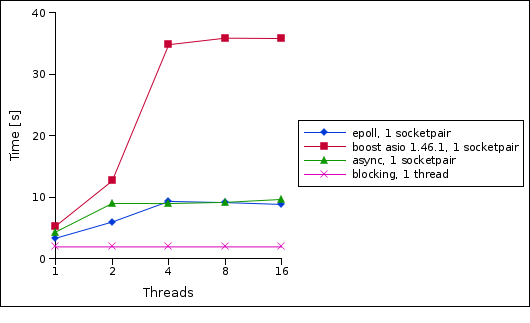
As expected, a blocking send/recv is the fastest option. But what's really interesting to see is that while epoll/asyncsrv only show a moderate slowdown with more worker threads, boost asio shows a significant slowdown. Note that there is only one message in transit, so we wouldn't expect a speedup anyway.
Ok, so let's add some concurrency by increasing the number of socketpairs to 16 (and decreasing the number of iterations accordingly).
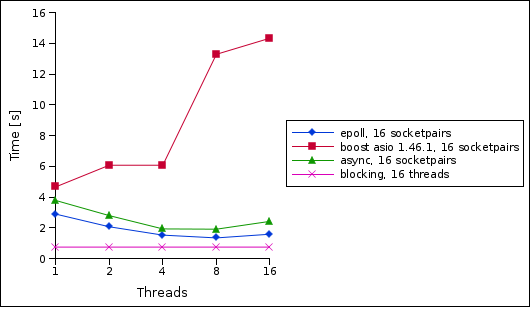
Now we can see that both the hand-written epoll loop and my async library scale reasonably well and provide a speed-up when the number of worker threads is increased. But boost asio again shows a significant slowdown.
Sat Mar 24 23:28:16 2012 GMT: Romeo and Juliet @ Royal Opera House
I have just been to a ballet performance of Romeo and Juliet at the Royal Opera House.
Wed Mar 21 22:08:09 2012 GMT: kevent on FreeBSD (Update)
The kevent multi-threading issue I have seen on FreeBSD seems to be related to the nevents parameter being set to 1. If I pass in something greater than 1 (ie 16), FreeBSD seems to behave much more reasonable. It's still strange, as I only ever expect to get one event (as there is only one packet in transit). Anyway, I have re-run the tests and the results look much nicer now:
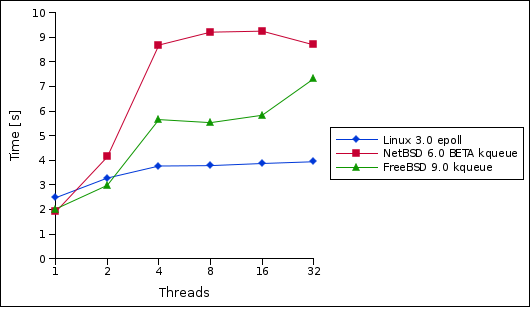
(tests were run on my dual-core AMD64 laptop with 400000 iterations - NetBSD and FreeBSD were run inside a KVM virtual machine, so might not be directly comparable).
Sun Mar 18 20:55:50 2012 GMT: Multi-threaded epoll/kqueue
I have been playing with edge-triggered epoll in a multi-threaded context on Linux for some time now, but have now also looked at kqueue on FreeBSD/NetBSD. I have to say that I am only using NetBSD (6.- BETA) and FreeBSD (9.0) in a KVM virtual machine, so that might affect things as well.
Anyway, I have written some simple test programs eptest.cc and kqtest.cc (for Linux and NetBSD/FreeBSD respectively). Essentially, they just create a datagram unix-domain socketpair and send 4-byte packets between them. Note that there is only ever a single packet in transit, so there shouldn't be any contention in user space (and there certainly is no explicit locking in the user space code). But I am creating n worker threads to handle event-triggered notifications when data is available to read on these sockets. So there is certainly some kernel space lock contention.
The interesting thing now is how the run-time changes depending on the number of worker threads on each platform. BTW, I am running this on my dual-core AMD64 laptop.
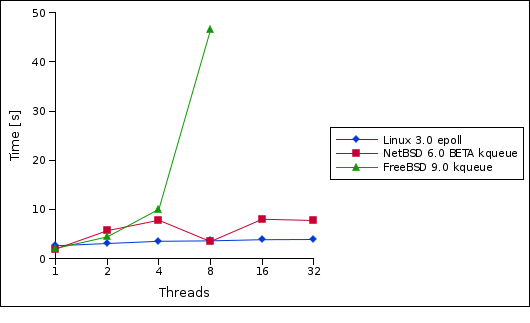
Interestingly, all platforms perform best with a single worker thread and NetBSD/FreeBSD beat Linux with a single worker thread. But the picture changes dramatically when the number of worker threads is increased. While I am only seeing a slight increase in the run time on Linux, NetBSD varies a lot more and the run time on FreeBSD seems to increase exponetially with the number of worker threads.
But as I said, I am not sure how KVM influences these results - so I am sure there is some more investigation to be done...
Mon Mar 05 23:17:44 2012 GMT: The Dream / Song of the Earth @ Royal Opera House
Fri Mar 02 23:00:37 2012 GMT: DNSSEC fully enabled for cmeerw.net
Fri Mar 02 00:03:53 2012 GMT: Rusalka @ Royal Opera House
Mon Feb 27 21:14:28 2012 GMT: Future Outlook for Eurozone Economy @ London School of Economics
Sat Feb 25 17:17:05 2012 GMT: Photos from Kona, HI